篇首语:本文由编程笔记#小编为大家整理,主要介绍了创建项目并初始化业务数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客相关的知识,希望对你有一定的参考价值。
今天给大家带来的博文是关于代码项目的初始化以及整个项目所需数据的初始化,其中包括,在
I
D
E
A
IDEA
IDEA中创建
m
a
v
e
n
maven
maven项目、数据加载准备、数据初始化到
M
o
n
g
o
D
B
MongoDB
MongoDB、数据初始化到
E
l
a
s
t
i
c
S
e
a
r
c
h
ElasticSearch
ElasticSearch等内容,通过这篇博文我们就可以把整个项目的框架搭建起来了。另外有一点很重要,关于代码的内容大家要注意可能和我的命名不同,当然允许不同,但是要注意修改相关的位置,相信能做到这里的读者应该都是有一定基础的,但还是要提醒一下,需要注意。当然,读者还是要有Scala和Maven的基础。下面就开始今天的学习吧!
项目主体用
S
c
a
l
a
Scala
Scala编写,采用
I
D
E
A
IDEA
IDEA作为开发环境进行项目编写,采用
M
a
v
e
n
Maven
Maven作为项目构建和管理工具
首先打开
I
D
E
A
IDEA
IDEA,创建一个
M
a
v
e
n
Maven
Maven项目,命名为MovieRecommendSystem。为了方便后期的联调,会把业务系统的代码也添加进来,所以可以以MovieRecommendSystem作为父项目,并在其下建一个名为recommender的子项目,然后再在下面搭建多个子项目用于提供不同的推荐服务。
在MovieRecommendSystem的pom.xml文件中加入元素
父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以MovieRecommendSystem和recommender下的src文件夹都可以删掉
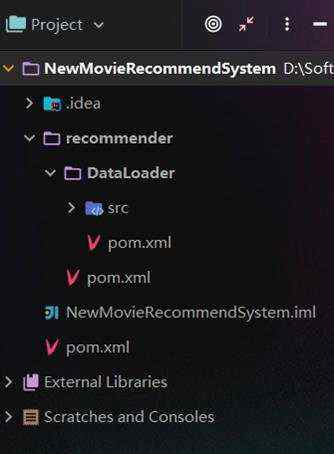
目前的整体项目框架如下:
整个项目需要用到多个工具,它们的不同版本可能会对程序运行造成影响,所以应该在最外层的MovieRecommendSystem中声明所有子项目共用的版本信息。在MovieRecommendSystem/pom.xml中加入以下配置:
<properties>
<log4j.version>1.2.17log4j.version>
<slf4j.version>1.7.22slf4j.version>
<mongodb-spark.version>2.0.0mongodb-spark.version>
<casbah.version>3.1.1casbah.version>
<elasticsearch-spark.version>5.6.2elasticsearch-spark.version>
<elasticsearch.version>5.6.2elasticsearch.version>
<redis.version>2.9.0redis.version>
<kafka.version>0.10.2.1kafka.version>
<spark.version>2.1.1spark.version>
<scala.version>2.11.8scala.version>
<jblas.version>1.2.1jblas.version>
properties>
首先&#xff0c;对于整个项目而言&#xff0c;应该有同样的日志管理&#xff0c;在MovieRecommendSystem中引入公有依赖&#xff1a;
<dependencies>
<!—引入共同的日志管理工具 -->
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>jcl-over-slf4jartifactId>
<version>$slf4j.versionversion>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>$slf4j.versionversion>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>$slf4j.versionversion>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>$log4j.versionversion>
dependency>
dependencies>
同样&#xff0c;对于maven项目的构建&#xff0c;可以引入公有的插件&#xff1a;
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.6.1version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
plugins>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
pluginManageme>
build>
然后&#xff0c;在MovieRecommendSystem/recommender/ pom.xml模块中&#xff0c;可以为所有的推荐模块声明spark相关依赖&#xff08;这里的dependencyManagement表示仅声明相关信息&#xff0c;子项目如果依赖需要自行导入&#xff09;
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-graphx_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>$scala.versionversion>
dependency>
dependencies>
dependencyManagement>
由于各推荐模块都是scala代码&#xff0c;还应该引入scala-maven-plugin插件&#xff0c;用于scala程序的编译。因为插件已经在父项目中声明&#xff0c;所以这里不需要再声明版本和具体配置&#xff1a;
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
plugin>
plugins>
build>
对于具体的DataLoader子项目&#xff0c;需要spark相关组件&#xff0c;还需要mongodb的相关依赖&#xff0c;在MovieRecommendSystem/recommender/DataLoader/pom.xml文件中引入所有依赖&#xff08;在父项目中已声明的不需要再加详细信息&#xff09;&#xff1a;
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
dependency>
<dependency>
<groupId>org.mongodbgroupId>
<artifactId>casbah-core_2.11artifactId>
<version>$casbah.versionversion>
dependency>
<dependency>
<groupId>org.mongodb.sparkgroupId>
<artifactId>mongo-spark-connector_2.11artifactId>
<version>$mongodb-spark.versionversion>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>$elasticsearch.versionversion>
dependency>








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 